Hier erfährst du von A-Z wie du eine gut strukturierte Paperless Konfiguration erstellst! Schau dir am besten die Video Reihe dazu an.
Wir benötigen folgende Docker;


Fang an mit Gotenberg und Apache-Tika-Server und Redis an hier musst du eigentlich nichts konfigurieren es sei den einer der Ports dort ist bereits belegt dann suche dir einen Alternativport.
Beim Paperless Container muss einiges eingestellt werden. Hierzu solltest du folgendes vorbereiten.
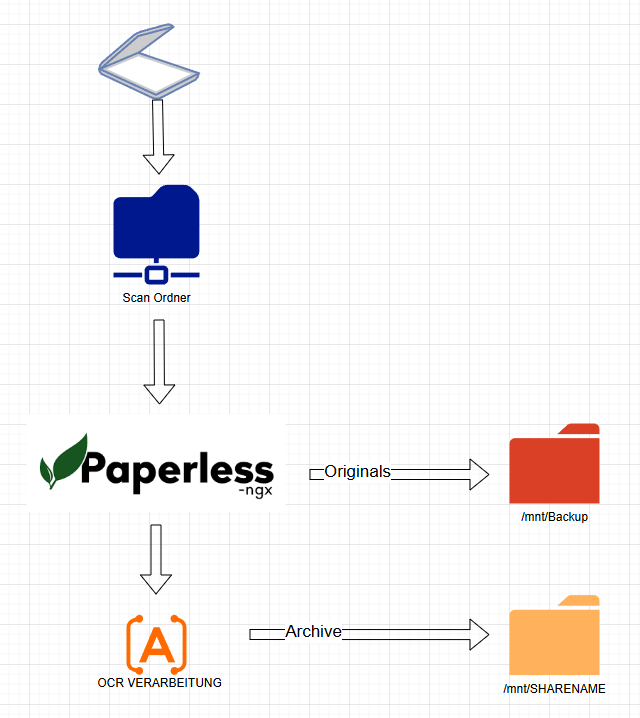
Erstelle für jeden „User“ einen Share in Unraid z.B. Manu / Selina / Family / Haus sowie ein Scan Share wo dein Scanner dann die Dateien ablegt und ein Backupshare falls du soetwas noch nicht hast.
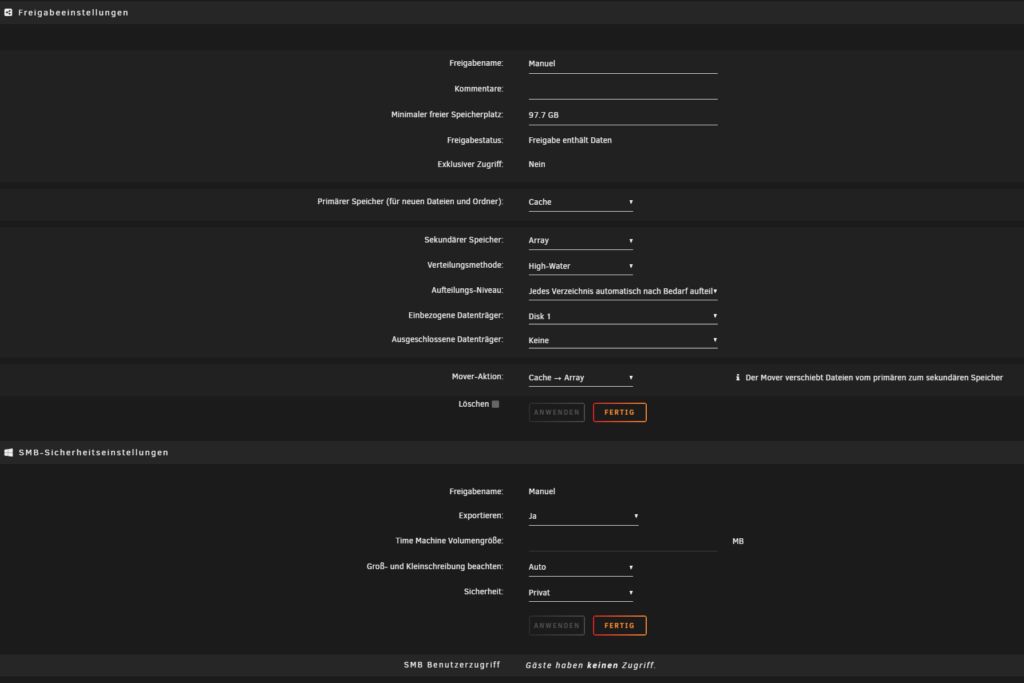
Ich lasse meine Shares hierfür auf Cache (SSD Pool) schreiben und verschiebe diese Daten dann auf mein Array.
Die Shares kannst du dann auf deinem PC als Netzlaufwerk verfügbar machen damit du auf die Datei Struktur zugreifen kannst. Wichtig ist hier nur keine Dateien zu löschen was aber sowieso blockiert sein sollte weil du hier nur Lese-Rechte hast.
Wenn du Dateien löschen musst dann kannst du das in Paperless erledigen.
Jetzt aber zur Paperless Docker Konfiguration:

Achte hier darauf das die Appdata auf deinen SSDs läuft und nutze hier am besten den direkten Pfad z,B, wie bei mir mnt/cache und nicht den mnt/user Pfad um dein System nicht unnötig zu belasten.

Den Media Pfad legen wir auf unser Backupverzeichnis. Wieso? Erklärung kommt gleich…

hier hinterlegst du deinen Scan Share wo dein Scanner in Zukunft die Dateien ablegt.

Kann erstmal leer bleiben.

Trage hier die IP von deinem Unraid und den Redis Port ein.


Jetzt kommt der spannende Teil.Wir werden jetzt den Paperless Pfad der archivierten Dokumente vom Media Ordner auf unsere User Shares umrouten. Das hat den Vorteil das die Originaldateien im Backupverzeichnis bleiben und unsere mit OCR gescannten Dokumente in Paperless auf einem Share liegen den wir einfach als Netzwerklaufwerk mounten können.


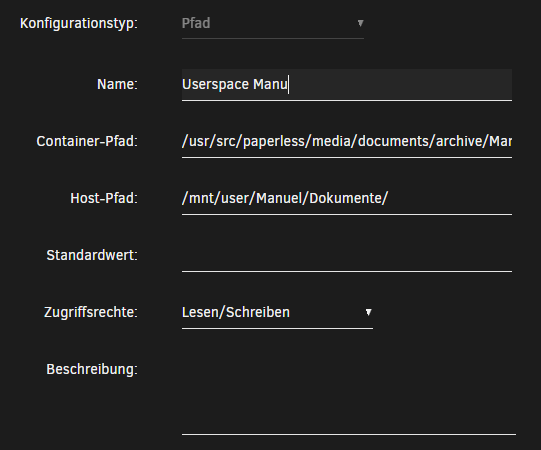
/usr/src/paperless/media/documents/archive/SHARENAME/Dokumente/
Als Hostpfad gebt ihr dann euer gewünschtes Share an.
Dadurch wird wie in dem Bild der Ordner Archive ausgelagert in deinen Share was dir eine saubere Struktur gibt.
Jetzt hinterlegen wir gleich noch ein paar Settings die unsere zusätzlich installierten Docker aktivieren und die Performance etwas anheben:
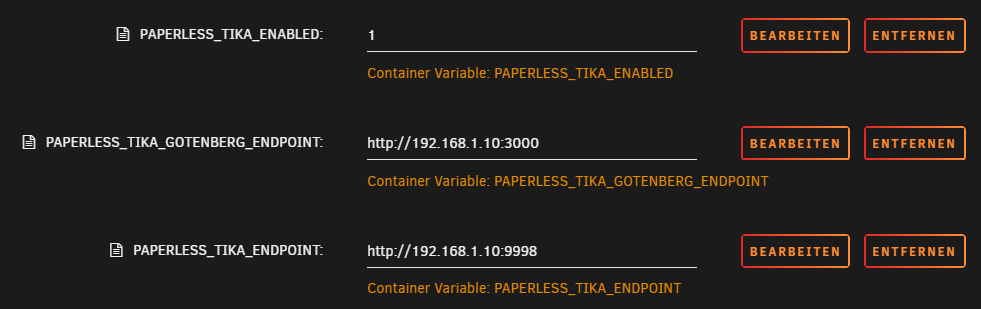
Diese müssen als Variable hinterlegt werden:
PAPERLESS_TIKA_ENABLED
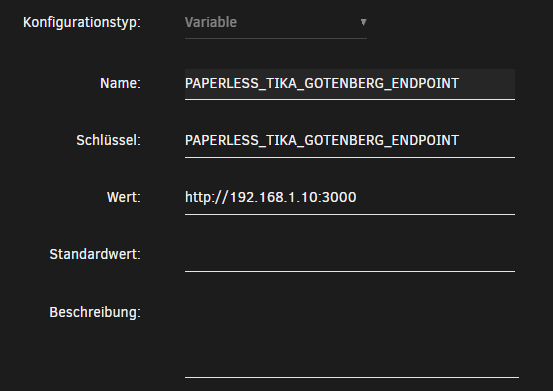
PAPERLESS_TIKA_GOTENBERG_ENDPOINT
PAPERLESS_TIKA_ENDPOINT
setzt hier die Werte wie im Screenshot (natürlich verwendet ihr eure IP und eure Ports.
Postgresql & Performance Boosts (optional)
Ihr könnt Paperless auch mit einer Postgresql betreiben was euch einige Performance Boosts „freischaltet“ – diese würden zwar auch teilweise mit der SQLite Datenbank funktionieren können aber schnell dafür sorgen das Dateien nicht importiert werden können weil die Datenbank nicht soviele gleichzeitige Anfragen erlaubt.
Um Postgresql nutzen zu können installiert noch folgenden Docker:

Theoretisch könnte man einen schon bestehenden Postgresql Docker nutzen – ich bin aber der Freund von einem eigenen Docker pro Anwendung.
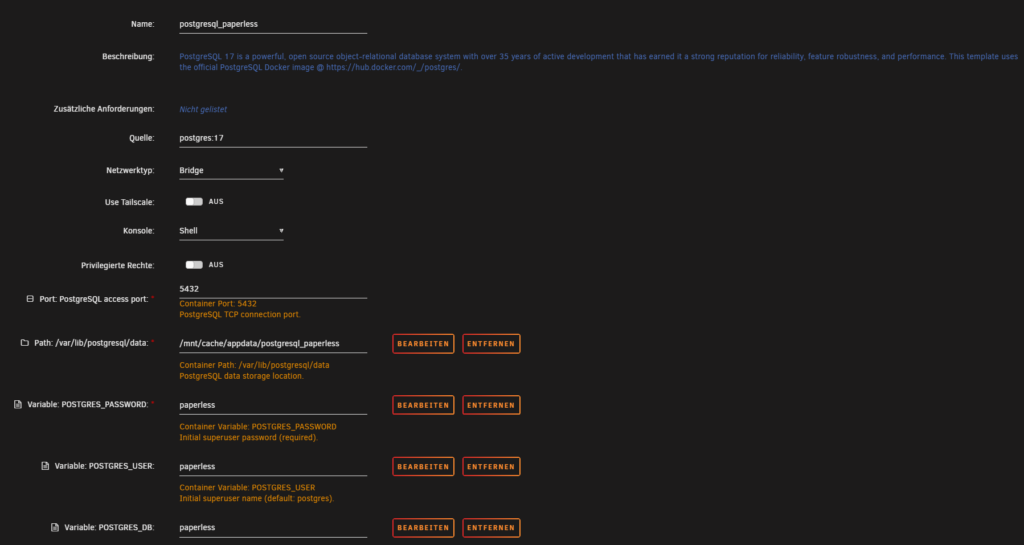
Hier bespielhaft die Settings. (ich ändere immer den Namen und das Appdata Verzeichnis zur eindeutigen Zuordnung)
Jetzt müssen wir im Paperless Docker noch einige Variablen eintragen:

PAPERLESS_DBENGINE PAPERLESS_DBHOST PAPERLESS_DBPORT PAPERLESS_DBNAME PAPERLESS_DBUSER PAPERLESS_DBPASS
Jetzt noch 3 Performance Booster (bitte nur für User die entsprechende Rechenleistung haben) diese werden auch als Variable hinzugefügt:
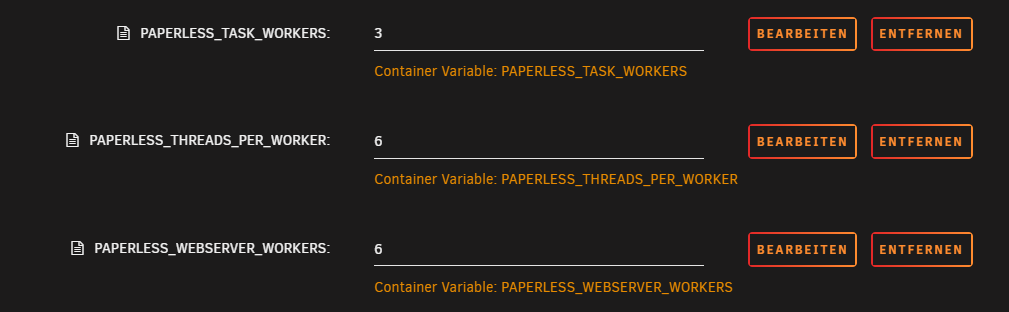
(bei zu vielen Worker kann es zu Fehlern kommen wenn man SQLite nutzt)
PAPERLESS_TASK_WORKERS
PAPERLESS_THREADS_PER_WORKER
PAPERLESS_WEBSERVER_WORKERS
Ihr könnt hier auch etwas weniger einstellen sollte euer Server kurz vorm explodieren sein wenn ihr die ersten Dokumente einlest.
Jetzt bist du startklar und wir können den Docker starten.
Danach musst du die Docker Console öffnen und folgenden Code eintragen um einen Nutzer zu erstellen:
python manage.py createsuperuser
Einen kleinen Fehler hatte ich noch mit OCR hierfür folgende Variable noch einfügen:
PAPERLESS_OCR_SKIP_ARCHIVE_FILE
als Wert tragen wir „never“ ein.

Als nächstes gehen wir dann meine Konfiguration Stück für Stück durch dazu aber mehr im nächsten Beitrag.


